Load balancing is an essential part of any application deployment to provide high availability, performance and security. We’ll focus on understanding and selecting scheduling and persistence algorithms and using the new LoadMaster Network Telemetry feature to validate the results.
Key takeaways:
- You’re balancing connections, not throughputs.
- To even the load across your server pool, you need to find the right combination of scheduling, persistence and timeout.
Scheduling & persistence briefly explained
There are two main decisions to be made when load balancing traffic:
When a new client connection comes in, which server in the pool should it be sent to? This is what the scheduling algorithm controls.
When a client returns for repeat connections how should they be identified so they can be returned to the same server as last time? This is the job of the persistence algorithm.
Together these two algorithms shape your traffic patterns to your server pool and therefore the load on each server.
Avoiding lumpy load
Although scheduling and persistence are simple concepts, getting them wrong can lead to a condition called lumpy load balancing.This is when you have very uneven load across your server pool. Avoiding this and getting an even distribution across your server pool is the main goal in load balancing.
Both scheduling and persistence play a role here and getting the right combination for your application is the key.
Basic load balancing methods
There are several basic methods with which you can achieve a uniform load across your application servers, each with its uses depending on the scenario.
Round robin
Round Robin is often used as a default scheduling method where each new connection is allocated to the next server in the pool. When each server has received one connection, it cycles back to the start of the list and loops over it again. This is the simplest scheduling method and if connections are very short and even and the application is stateless, this can work well without much trouble. In this simple case you don’t need persistence and repeat connections keep getting redistributed around the server pool, which keeps it pretty even.
Problems start to occur when connections are uneven in load and when client sessions last longer, such as when state needs to be kept and persistence is used (e.g. a web mail or CRM session). This can result in very uneven load building up over time as some servers get hit with heavy and long-lasting sessions while others receive light and short-lasting sessions. Over time the number of connections per server starts to become uneven as does the workload on the server.
Least connection
Least Connection is another method that can do a better job evening out the load over time. Instead of cycling around the server pool, Least Connection looks at the number of current connections per server and chooses the server with the least number of connections at that time. This means that it keeps rebalancing the connections per server over time and prevents them from becoming too uneven.
Even with Least Connection you can end up in a very uneven state when persistence is used because persistence overrides scheduling for return clients. It all depends on how you identify a returning client connection. Source IP is a common and simple method for this but that’s the trouble – it’s too simple. If a large number of clients are behind a NAT device they will all appear as a single client and all be sent to the same server in the pool. This can also happen if users are coming from a terminal server. On the other hand, mobile clients can frequently change source IP as they roam the network and lose their session state as they keep getting rebalanced.
Active cookie
For web applications, using a method like Active Cookie is a much better way to identify individual users. The load balancer injects a cookie with a unique identifier each time a new client opens a session. This allows the load balancer to track that client over time regardless of where their traffic is originating.
The final factor is the persistence timeout. This controls how long a client persistence record is kept before it gets re-balanced to another server. Too short and client session state will get lost, too long and you run the risk of lumpy load building up on some servers. If you’re unsure, setting it to an 8 hour window is a safe bet to line up with a standard work day, however, knowing your application patterns and how long a user generally stays in a session is best. Longer persistence timeouts mean more chance that you'll end up with uneven load on your servers.
You can see from this simple example how both scheduling and persistence options contribute to the load that accumulates on each server and how important it is to understand your application patterns to get the right configuration.
You can find details of all scheduling methods and persistence methods in our Kemp Support Knowledge Base.
Fine tuning with network telemetry
With the new LoadMaster Network Telemetry feature you can turn the load balancer into a source of flow data for your Flowmon Collector. With this you can get instant feedback in your Flowmon dashboard on how connections and throughput are accumulating on each server and detect lumpy load balancing conditions. This allows you to easily monitor and respond to fine tune your configuration for each application.
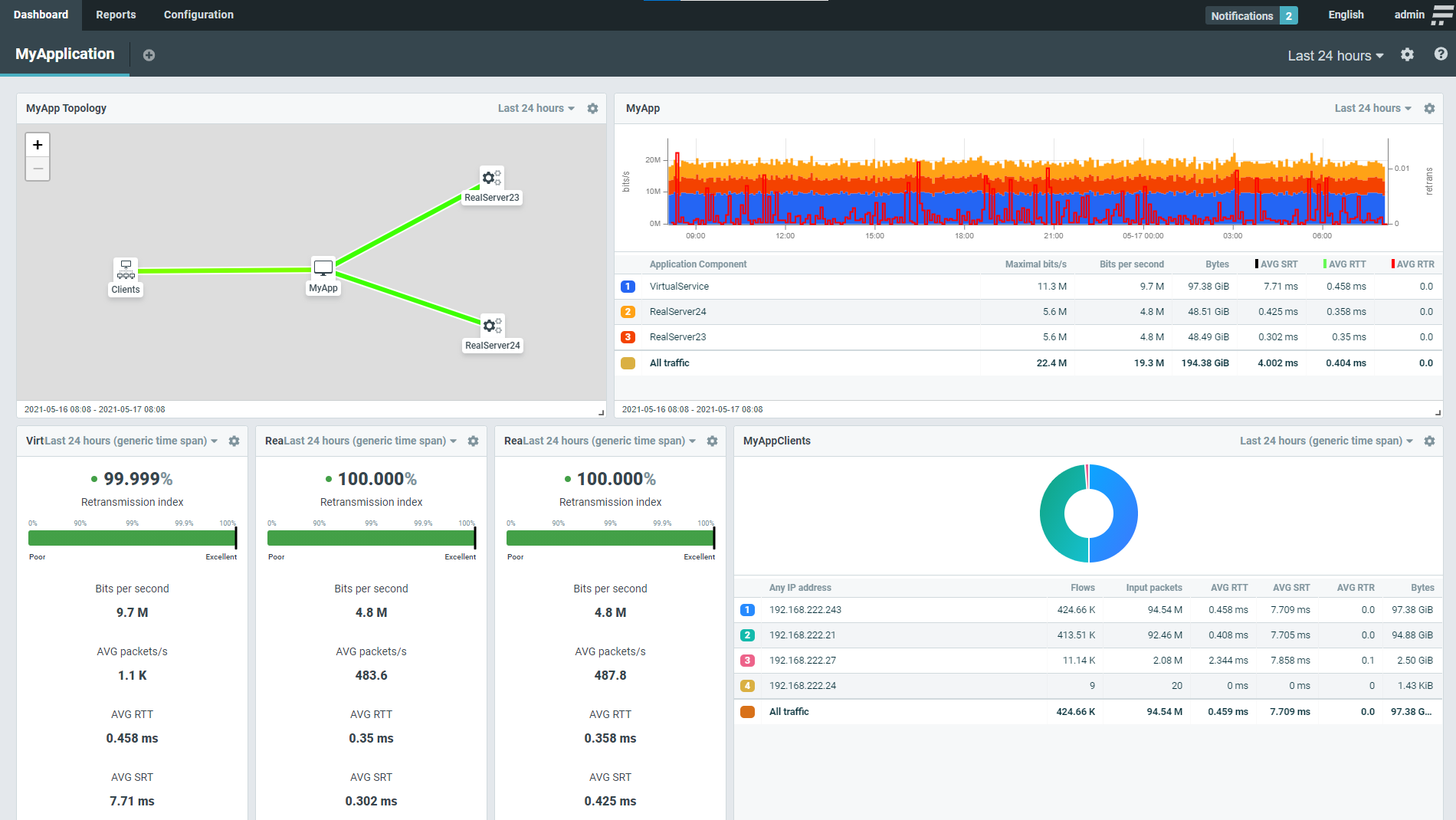
Key performance metrics and traffic statistics on the Flowmon dashboard
On the Flowmon Collector side you can create a comprehensive dashboard that shows key performance metrics of your application based on Network Telemetry provided by the LoadMaster. The application topology visualizes bandwidth utilization and shows if the application traffic is load balanced equally to individual servers in the pool. The traffic chart shows volumetric and performance metrics on a timeline to provide an understanding of traffic patterns in the application workload. Key performance metrics such as server response time and round trip time allow you to distinguish between issues on the network and application side that are a common source of finger-pointing between teams. Moreover, these metrics can be compared between individual servers in the pool and point to a server that might not be performing as expected. Top statistics shows per client data sorted by worst server response time, amount of transferred data and number of requests (flows).
Summary
It’s very important to remember that you’re balancing connections, not throughput. If connections vary in throughput even connections per server won’t equal even throughput per server. Choosing the right combination of scheduling, persistence and timeout are the key to even load in your server pool.
If you find you’re suffering from lumpy load balancing and having trouble getting the configuration right remember you can always contact our world-class support team for help.
Are interested in trying a Kemp load balancer for yourself? Give the Free Load Balancer Trial a go. If you experience any issues, contact us. We’ll be happy to assist you in any way.