Regardless of how network problems come about, it is necessary to eliminate them as quickly as possible and ideally prevent them recurring in the future. There are different types of software for this purpose, including antivirus, firewall, and IDS. But before a problem can be eliminated, it has to be detected regardless of how they have occurred.
Quick navigation:
- What is a network anomaly?
- What is an anomaly detection system?
- Differences between active and passive network monitoring in network anomaly detection
- What is anomaly detection used for?
- Anomaly detection via methods
- What are the differences between network anomaly detection using signatures and baselines?
- Use of machine learning for anomaly detection
- Problems in anomaly detection (false-positives, encrypted traffic)
What is a network anomaly?
Problems in computer networks are detected as traffic anomalies that they cause. In general, an anomaly is something that goes against expectation. For example, a damaged switch may create unexpected traffic in another part of the network, or that new error codes begin to appear when a service is down. Network troubleshooting is founded on network anomalies.
The first method of classifying anomalies is based on the way they differ from ordinary communication. Anomalies can vary either by the type of data transferred (behavioral), by the amount of data transferred (by volume), or by both criteria. Another way of classifying anomalies is according to their cause:
- Non-human error - e.g. equipment failure or radio communication interrupted by weather;
- Human error - e.g. network service outage caused by misconfiguration or an accidentally disconnected network cable;
- Malicious human activity – e.g. an insider attack, where a disgruntled employee of the company damages the network printer or an external attack where an adversary tries to disable the network and cause reputation damage.
What is an anomaly detection system?
Anomaly detection requires constant monitoring and analysis of selected network metrics. Anomaly detection system covers a scenario, when something unexpected is detected and the analysis evaluates this as an anomaly, it can be reported to the network administrator.
There are two main categories of network monitoring that allow detecting anomalies:
Passive network monitoring
The computer network includes probes that receive data from the network and evaluate it. This data can be either intended directly for the probes (for example, events sent via the SNMP protocol) or it can be a copy of the production traffic, which occurs in the network whether the probe is connected or not.
Active network monitoring
Networks may also contain probes as in passive monitoring, but these probes generate additional traffic, which they send through the network. With the help of this traffic, it is possible to regularly determine the availability or general parameters of the tested services, network lines, and devices.
Differences between active and passive network monitoring in network anomaly detection
It may seem that active monitoring adds to the capabilities of passive monitoring, making it automatically the better option. Yet, the problem with active monitoring is that it generates additional data in the network. Therefore, in active monitoring, the monitoring devices become part of the production network (which brings with it, for example, security risks) and the monitoring is consequently not fully transparent. Another potential problem is that the monitoring data itself can affect the functionality of the network and thus be a source of problems and anomalies (for instance, it can increase the load on an already busy server). Given these disadvantages, this article focuses only on the passive monitoring of network anomalies.
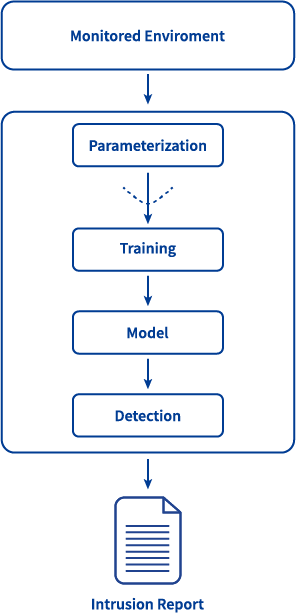
In general, anomaly detection can be divided into several basic components; see Figure 1 (diagram on the right side). They have the following functionalities:
- Parameterization - The monitored data is separated from the input data in a form suitable for further processing.
- Training - When this mode is selected, the network model (trained status) is updated. This update can be done automatically as well as manually.
- Detection - The created (trained) model is then used for comparing data from the monitored network. If it meets certain criteria, an anomaly detection report is generated.
What is anomaly detection used for?
- Ransomware detection - detection is done via looking for a signature of the executable file
- DDoS attack detection - by comparing the amount of the current traffic with the expected amount, the attack can be detected
- Botnet activity tracking - with a list of known botnet command and control servers, it is possible to detect connections with those servers
- Dictionary attack detection - by counting the number of login tries and comparing the number with threshold values, it is possible to detect attempts to hack an account
- Link failure detection - this can be identified by detecting the increased amount of connections on the backup link
- Incorrect application configuration detection - this can be detected by an increased amount of error codes within application connections
- Server overload detection - by detecting a decrease in quality of experience, it is possible to detect overload services or servers
- Suspicious device behavior detection - by creating behavior profiles and checking if some device behaves outside of created profiles, it is possible to detect suspicious activity
Anomaly detection via methods
Signatures or knowledge-based
A signature accurately describes what type of data the system looks for. An example of a signature can be searching for a packet that has the same source IP address as the destination IP address, or when searching for a specific content in the packet.
Baseline or statistical-based
A baseline describes an amount of data transferred that share certain common features. For example, it can be the number of detected TCP connections per every 5 minutes. An anomaly occurs when the current value (the number of queries over the last 5 minutes) digresses from the learned baseline in a significant way; see Figure 2. Another example is seeking a change in packet distribution according to the ports they are headed to. Figure 3 shows a case where an anomaly manifests itself as an increase in the amount of packets sent to one destination port.
Figure 2: Anomaly detection according to a change in the amount of TCP connections detected [A Signal Analysis of Network Traffic Anomalies]
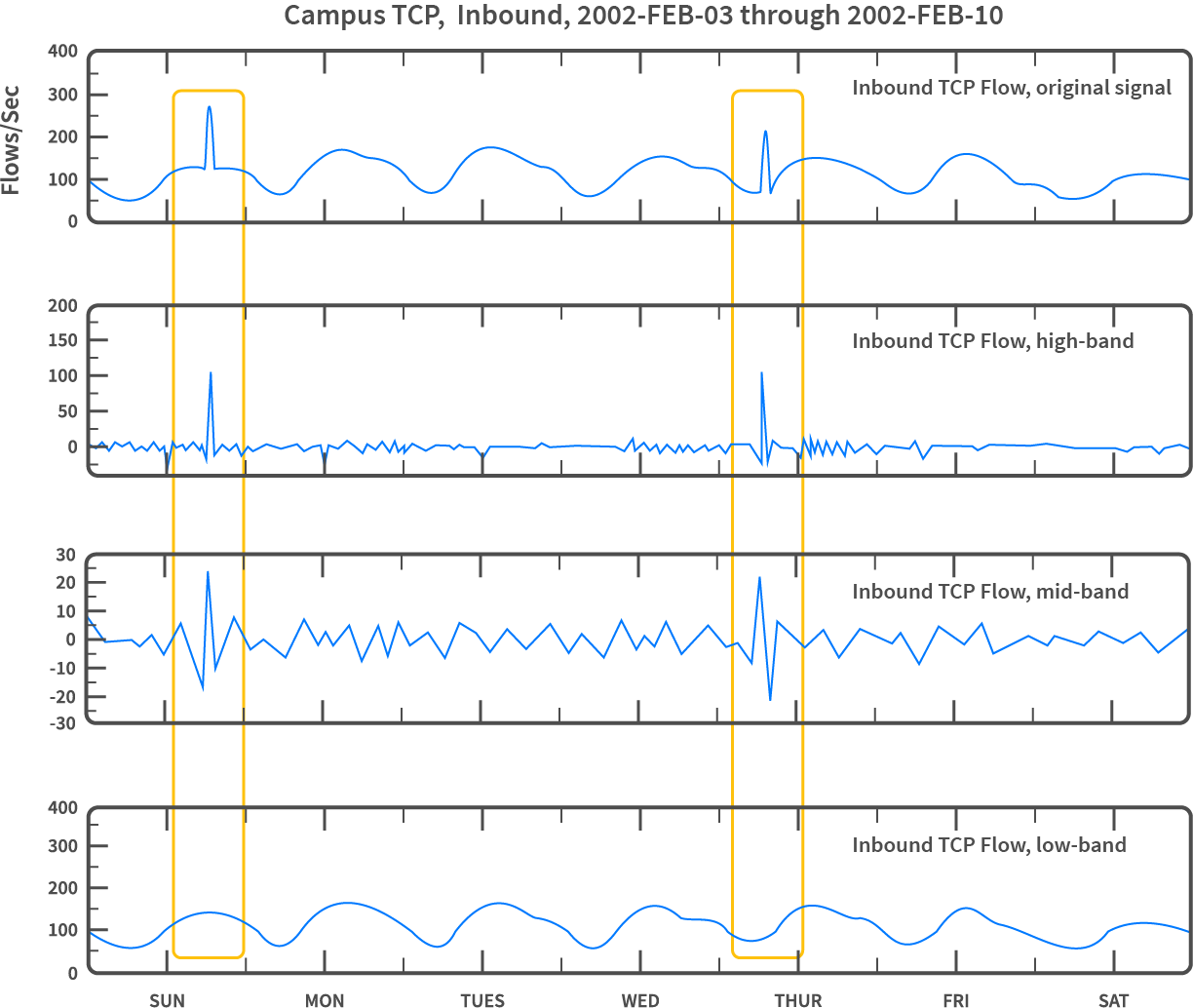
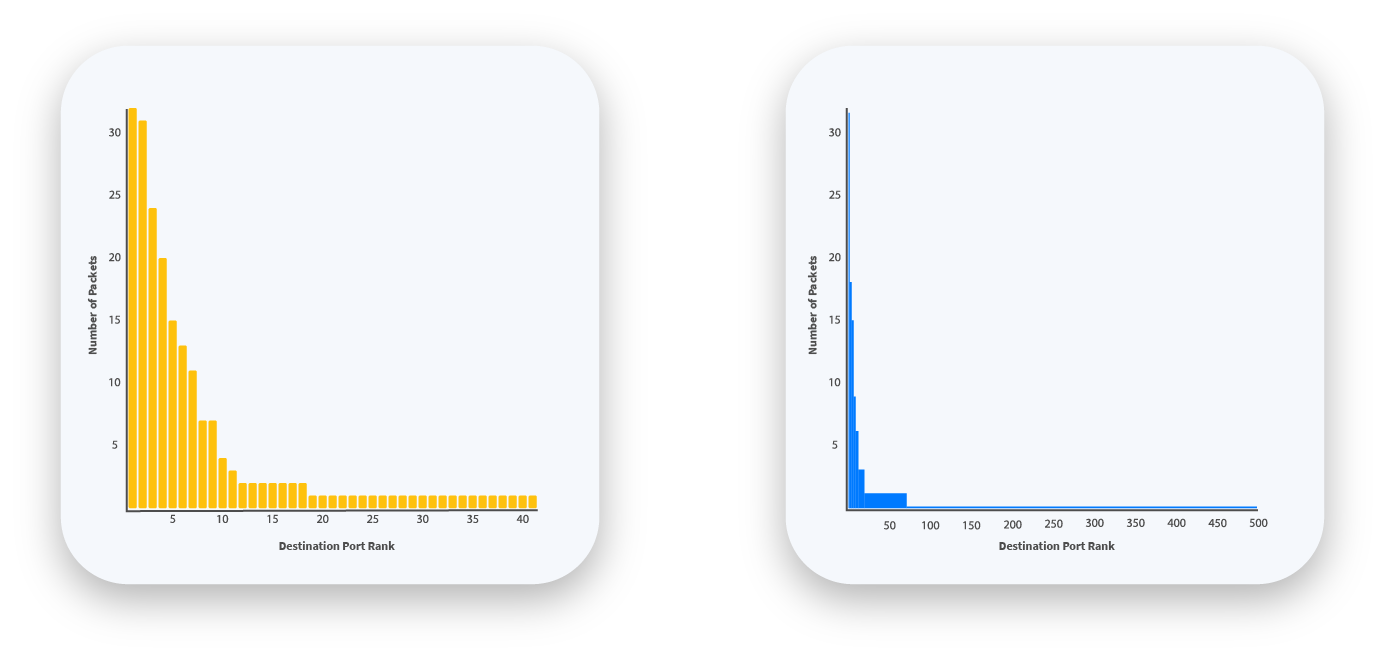
Figure 3: A change of the distribution of packets by destination port. When transferring large amounts of data to a single port, the resulting distribution changes significantly.
What are the differences between network anomaly detection using signatures and baselines?
Table below compares the use of signatures and baselines.
| Attribute | Signature | Baseline |
|---|---|---|
| Ability to detect known errors or attacks | High - if the signature exists | Low - deviation from the baseline is not tied to a specific situation |
| Ability to detect unknown errors or attacks | Low - if no signature exists for the error or attack, it cannot be detected | High - deviation from the baseline is not tied to a specific situation |
| Difficulty of knowledge base maintenance | High - existing signatures require updates and new ones must be created | Low - the baseline can be recalculated automatically over time |
| Detection speed | Fast - the moment some data meets the detection criteria, the anomaly is found | Fast - the moment some data meets the detection criteria, the anomaly is found |
| Deployment speed | Fast - anomalies can be detected immediately after deployment | Slow - the baseline needs to be trained before it can start detecting |
| Number of false-positive detections | Smaller - if the signatures are well-defined, ordinary packets will not meet their criteria | Larger - any fluctuation can cause an anomaly |
While anomaly detection using signatures is fast and accurate, it can only work on those traffic anomalies for which a signature is known. On the other hand, machine learning-based detection is slower and turns out a larger number of false positives but is capable of exposing new and modified anomalies for which no signature exists. In general, it is not possible to detect all anomalies without encountering any false positives. Therefore, a balanced approach is generally advised.
Use of machine learning for anomaly detection
In order for the signatures to be accurate and to detect known anomalies in the network, they have to be created manually using the knowledge of each problem or attack. Baselines, on the other hand, can make use of machine-learning algorithms. The primary advantage of using machine learning is that the baseline can change over time depending on what data was actually detected, making it possible to learn from previous results.
Machine-learning algorithms (e.g. heuristics) are used by anomaly-based intrusion detection systems, which function on the principle of seeking deviations from a learned norm.
The advantage of using machine learning is that the methods rarely require any knowledge of the network being monitored but they can still learn the expected behavior and detect anomalies. There is, however, a downside in that if an error manifests itself by a gradual increase of certain attributes, no anomalies will be detected. Instead, the learned model will slowly accommodate the new increase in these attributes and no detection will occur. A sophisticated attack can take advantage of this to avoid detection.
Problems in anomaly detection
The reality of anomaly detection is not as straightforward as it may seem. Eventually, There will arise a problem that will significantly limit the capability of anomaly detection. This section describes two of the most critical issues.
False-positive detection
Distinguishing between normal operation and an anomaly is not always easy. What may have been normal traffic yesterday can become an anomaly tomorrow. This is because the transmitted data changes whether there is a problem (anomaly) in the network or not. This is why detection rather operates with probability scores. While every system or method can use it differently the basic idea is the same. Each detected event is assigned a score and if this score exceeds a predefined threshold, it is marked as an anomaly.
The threshold for detecting anomalies determines the sensitivity of the detection. If the sensitivity is too high, problems or anomalies will be quickly detected but at the cost of an increased number of events mislabeled as anomalous. These mislabeled events are referred to as false positives,On the other hand, if sensitivity is low, the number of false positives decreases, but so does the number of correctly detected anomalies - the abnormality of some anomalies will not be high enough, allowing them to go without being discovered.
An example of a false-positive event is when an unexpected update of an operating system transfers a large volume of data, or when an unexpected circumstance prompts an abnormal number of customers to connect to the company's e-shop at the same time.
Generally speaking, it is not possible to ensure that all anomalies in the network will be detected and at the same time that there will be no false positives. The reason false positive events are actually an issue is that during automatic event processing, legitimate traffic or a service might be identified as problematic and its activity will be limited. At the same time, processing and analyzing these anomalies manually requires an enormous amount of time and effort.
Encrypted traffic monitoring challenges legacy anomaly detection
For reasons of privacy and security within computer networks, data encryption is expanding and improving. Encrypted communication also affects the detection of anomalies because data encryption reduces the amount of data that monitoring and analysis can work with. For example, in the monitoring of encrypted email communication, no email addresses are available.
It is important to know at what level the encryption takes place. Most communication is encrypted only at the application level, which means it is still possible to perform statistical analysis of the IP addresses, destination ports, etc. Thus, encryption does not prevent the detection of anomalies, but significantly limits what types of anomalies can be detected. Unfortunately, adversaries and various malware scripts are also aware of this fact and hide their activities in encrypted communication to avoid detection.
